There’s a thing going around the engineering blogs and Hacker News right now: AI killed Agile, Waterfall is back, write your specs up front, welcome to “Waterfall 2.0.” You may have seen the Medium piece titled Agile Is Dead. AI Killed It. Welcome Back, Waterfall.. Hmmm.
And once I followed the logic far enough, I ran into a second question that nobody seems to want to answer out loud: if the agent writes the code, who actually reads it?

The waterfall didn't go away — it got compressed into a loop that runs in minutes instead of months.
The headline “Waterfall is back” is wrong. AND… it’s right. BOTH can be true.
Let me explain.
What Everybody Actually Agrees On
I’ve been chewing on this for a while, especially after the Thoughtworks “Future of Software Engineering” retreat report dropped earlier this year (I wrote about that one here). So I went and read just about everything I could find on the topic and tried to line it up against the retreat findings. Here’s where I net out.
Strip away the branding and almost every source — celebrants, skeptics, Thoughtworks — agrees on the same thing:
Engineering rigor has moved upstream. The highest-leverage work is no longer typing the code. It’s writing the spec, the acceptance criteria, the tests, the constraints, the context the agent gets to see. LLMs are pattern completers. They can’t read your mind. Garbage spec in, garbage code out — just faster than before. Which cannot scale.
That’s it. That’s the argument. Everything else is people fighting over the label.
Why “Waterfall” Is the Wrong Word
Look — I’ve been around since before Agile had a capital A. I remember real Waterfall. The thing that killed Waterfall wasn’t writing specifications. Specifications are fine. Specifications are great. The thing that killed Waterfall was that discovering your spec was wrong months later, after lots of code had been written - and fixing it cost a fortune because writing code was the most expensive part of the process.
That penalty is gone. Writing the code is the least expensive part of the process. With agents, you write a spec, regenerate in fifteen minutes, see it’s wrong, fix the spec, regenerate again. The spec-to-running-code loop is minutes, not months. The key reason Agile was invented was to account for the high cost of writing code, so yes, that part of the Agile value proposition is no more.
This is what people are calling Spec-Driven Development (SDD) — specify → plan → tasks → implement, where the spec is the source of truth and the code is a generated, somewhat disposable artifact. GitHub’s Spec Kit, AWS’s Kiro, Tessl, and the lightweight CLAUDE.md / AGENTS.md conventions are all variations on the same idea: write the spec first, let the agent execute, keep a human in the loop at each step.
Jeff Levin calls them “mini-waterfalls” — research deeply, plan precisely, dispatch to a disposable agent, audit the result, repeat. Entire cycles in hours instead of months. An Agile purist would squint at that and recognize most of it.
So when somebody tells you Waterfall is back, what they usually mean is “I write specs now and it works great.” Cool. That’s not Waterfall. That’s just being a competent engineer with a new tool that rewards precision.
The Fault Line: Loop Length and Batch Size
Here’s the part the headlines miss.
The actual disagreement in the discourse isn’t whether to write specs up front. Everybody agrees you should. The disagreement is about how long the feedback loop is allowed to get and how big the batches are.
| What you’re doing | Verdict |
|---|---|
| Spec up front, minutes-to-days loop, continuous human review | Endorsed by basically everyone |
| Spec up front, months-long loop, deferred customer validation, big-bang release | Condemned by basically everyone |
Same workflow at the top. Same workflow at the bottom. The only difference is loop length and batch size. That’s the line.
This is exactly where Thoughtworks lands too. They validate the kernel — yes, rigor moves upstream to specs, tests, EARS-style requirements, risk tiering. But they explicitly reject “Agile is dead.” In fact they report teams compressing sprints to one week and rediscovering XP practices — pair programming, ensemble work, continuous integration — precisely because tight loops are what agent-assisted work needs.
And the bit that should make everybody pumping “Waterfall 2.0” pause: Thoughtworks flags the drift toward large infrequent releases as an active regression that reverses a decade of DORA evidence. The very thing the loudest “Waterfall is back” voices celebrate — big batches, front-loaded everything — Thoughtworks calls a defect.
That should tell you something.
The Trap Nobody Talks About
Arin Sime’s piece nails the danger more clearly than anybody else’s. The risk isn’t that AI development is inherently Waterfall. The risk is that organizations with latent Waterfall instincts will use spec-generation as license to do the bad thing they always wanted to do — front-load requirements, skip customer validation, equate a fancier document with a better outcome, and ship one massive thing every quarter.
Geesh. If you’ve worked in a big enterprise for more than five minutes, you know that org. You worked there. So did I.
The tool doesn’t make the org Agile. The tool doesn’t make the org Waterfall. The org does that all on its own. AI just hands them a more sophisticated way to execute whichever instinct already won.
Sime’s reconciling distinction is the most useful thing I read in the whole survey: spec-driven work at the feature level is fully Agile-compatible. It’s basically disciplined acceptance criteria. The same practice at the whole-project level collapses back into Waterfall. Same technique. Wildly different outcomes. The deciding factor is whether the human review loop stays intact.
The Elephant in the Room: Do Engineers Read Every Line?
Everything up to this point has been about the shape of the loop — how long it should be, how big the batches, where the rigor lives. But a loop only matters if something is actually evaluating each iteration. Otherwise it’s just a faster way to ship broken code. So the obvious downstream question is the one nobody wants to answer out loud.
If the agent writes the code, who reads it? Every line? Some lines? None?
This is THE question. And my honest answer - that will cause a stir - is: it depends entirely on how good your tests are.
If your tests fully cover what the spec required — every contract, every edge case, every failure mode, every invariant — then no, you do not need to read every line. The tests are reading the code for you. Every run. Deterministically. Forever. The agent can rewrite the whole implementation tomorrow and you’ll know in thirty seconds whether it still works.
That. That is the actual superpower of this era. Not the agent. The tests.
And the corollary lands hard: deriving tests from the spec is the new craft. Spec-driven development without rigorous test generation is just documentation theater. Spec-driven development with tests that exercise every claim the spec makes is something genuinely new — a feedback loop that can verify the agent’s work without a human reading the diff. Spec says what should be true. Tests prove it’s true. Code is the cheap, regeneratable thing in the middle.
But hoo boy — what does “tests good enough to skip code review” actually mean in practice? What coverage do you need? What kinds of assertions? Property-based? Mutation testing? Contract tests at the boundaries? How do you generate them without the agent writing tests that confirm its own broken implementation? That’s a whole post unto itself, and it’s coming. Stay tuned.
Here’s the catch though: most teams do not have tests anywhere near that good. Sparse coverage, flaky suites, happy-path-only assertions — if that’s where you are, you cannot trust agent output on tests alone. You’re back to reading code. And THAT is when the risk tiering from Agency is More Important Than Code Quality kicks in:
- Line by line. Payments. Auth. Safety-critical paths. Anything that runs without a human in the loop in production. The pacemaker tier.
- Read the diff, spot-check the gnarly parts, lean on whatever tests you do have. Most internal code. The “is this doing roughly what I asked for” tier.
- Trust the types, glance at the shape, ship it. Prototypes, throwaways, anything you’ll regenerate in fifteen minutes if it’s wrong. The let-it-rip tier.
Thoughtworks calls this risk tiering — verification matched to blast radius. I went deeper in The Future of Software Engineering: the every-line-manually-inspected model was already breaking under volume before agents made it worse. And as I argued in Vibe Coding: A Practical Review, the engineers picking this up fastest are the ones who already learned to verify results rather than control every keystroke — leads, managers, anyone who’s spent years delegating to humans. The neural pathways are set.
Here’s the reframe that took me the longest to land on. The real question was never “do you read every line.” It was always trust.
Look — I’m a VP. It’s been years since I was looking at even larger parts of the code. Nobody at my level does. What I have instead is a network of trust I built deliberately, one engineer at a time. I trust certain seniors to review certain kinds of changes. I trust the people they trust. I trust the CI pipeline because I trust the engineers who built it. I trust the on-call rotation to catch the thing nobody else did. That network is the actual product of years of hiring, mentoring, and watching people work under pressure.
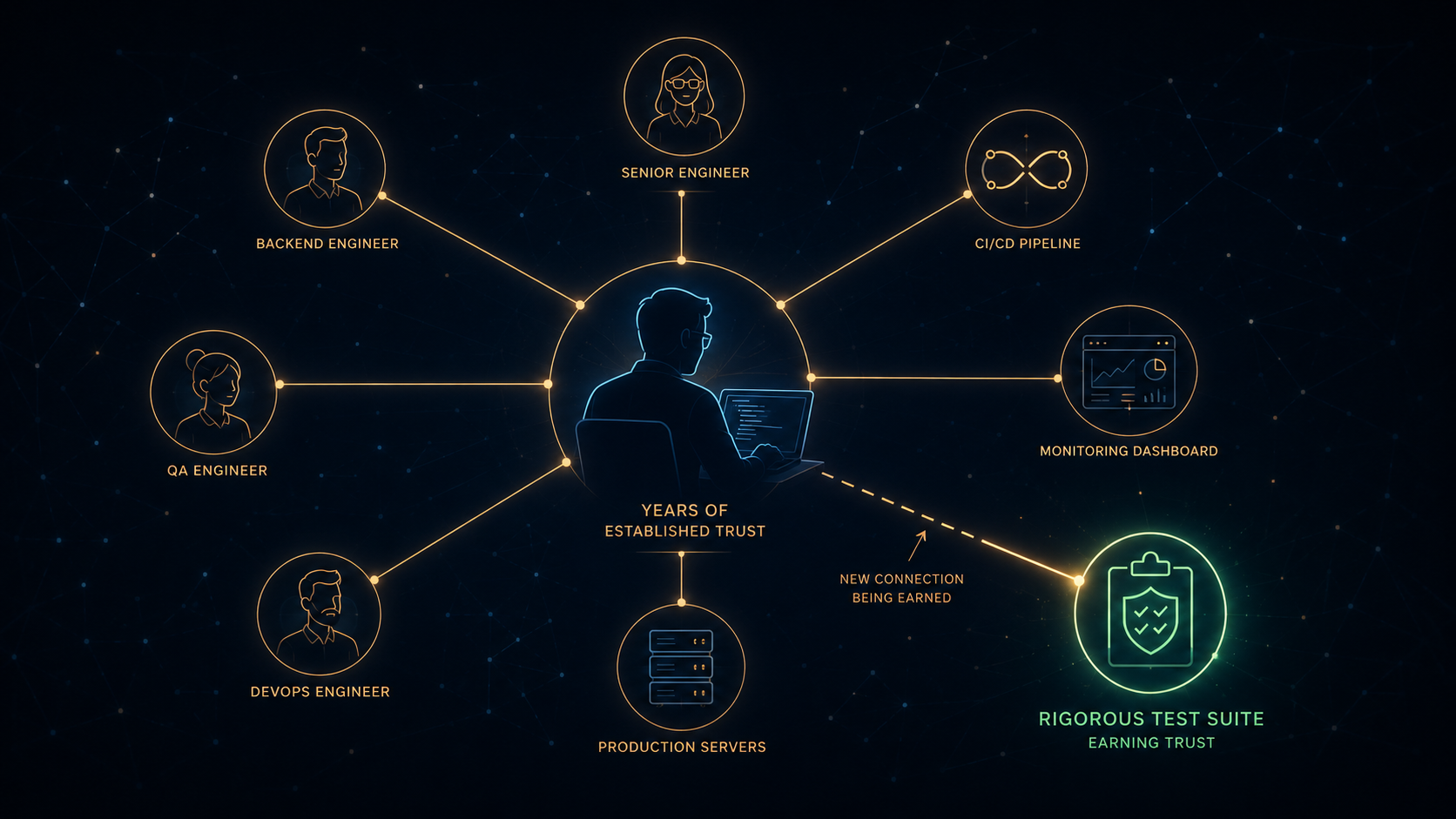
The network of trust around a senior engineer — and the new node trying to earn its way in.
That is how a thousand-line PR ships without me reading line 400. Not because the code was perfect. Because the system around the code was trustworthy enough that line 400 was probably fine — and if it wasn’t, somebody downstream would catch it. The good seniors weren’t skimming. They were leaning on the network they’d helped build.
So the real question for this era isn’t “how many lines do humans read.” It’s: can we build a test suite that earns the same kind of trust I currently grant a senior engineer?
That’s a hard bar. A senior engineer brings taste, context, memory of past incidents, pattern recognition you can’t articulate. Tests bring repeatability and exhaustiveness. Different shapes. But they answer the same underlying question — should I trust this code is doing what we said it should do? — and either the answer earns trust or it doesn’t.
This is exactly why the review loop itself can never be skipped. Trust isn’t built by skipping evaluation. Trust is built by running the loop so many times you stop having to think about it. Whether the evaluator is a senior engineer reading a diff or a battery of property-based tests grinding through edge cases, what builds trust is the loop running, every time, without exception. Skip the loop and trust collapses — vibe code that compiles, ships, and fails three weeks later in a way nobody can trace. That’s the failure mode Martin Fowler keeps pointing at. He’s right.
The big shift is what I am extending trust to. For most of my career, that trust went to humans I had worked with. Now some of it has to go to test suites that encode what the spec said. That’s a new kind of trust to grant — and the engineering work of the next few years is figuring out what testing has to look like to deserve it.
More on that soon.
Conclusion
The most accurate statement is not “Waterfall is back.” It’s: upfront rigor is back, inside short Agile loops.
If you take one thing from this:
- Yes, write the spec. Treat it as the highest-leverage artifact. Specs are context, not contracts — they raise the hit rate, they don’t eliminate review.
- Yes, derive tests from the spec. That’s where the new craft lives. Tests are how the loop closes when humans can’t read every line, and the only candidate strong enough to inherit the trust we used to grant senior engineers. (More on what those tests have to look like in a coming post.)
- No, you do not read every line — and honestly, you weren’t really doing that before either. Tier your review to the blast radius until the tests are good enough to do it for you. The loop stays intact; the depth doesn’t have to be uniform.
- No, that does not mean six-month Inception phases. If your dev cycle is two days, your feedback cycle should be two days. Not two quarters.
- No, “Agile is dead” is not what’s happening. The teams getting durable results are not writing the longest specs. They’re the ones keeping the feedback loop short while moving rigor upstream.
- And yes, if your org sees AI as a license to go back to gated phases and quarterly releases, that’s the failure mode to watch. It’s not a tool problem. It’s an org problem. Same as it ever was.
Both can be true. Waterfall — the part of it that was actually about thinking before coding — is back. Waterfall — the part of it that was actually about batching everything up and finding out you were wrong six months later — should stay dead.
Don’t get those two things mixed up.
And while you’re sorting out the waterfall question, don’t miss the one underneath it: the trust you used to grant senior engineers has to start going somewhere new, and the only candidate at scale is a test suite good enough to deserve it. That’s the real engineering work of the next few years. Keep an eye out — I’ll be writing about exactly what that bar looks like soon.
If this helped, drop me a note on LinkedIn. And if you disagree, drop me a note anyway. I’d rather be told I’m wrong than stay wrong.